0. INTRODUCTION
Numberous works about neural network language models (NNLMs) have been published, but they are all about the whole architecture of NNLMs or optimization techniques for NNLMs. The details about building a neural network language model are seldom introduced, but many implementation details have significant influence on the performance of NNLMs. In this post, some tips for implemetation details of NNLMs are included.
1. INITIALIZATION
The initialization of nerual network language models has a significant effect on the training, and the parameters of neural network language models needed to be initialized include feature vectors of words and weight matrixes of neural network. Each parameter is commonly initialized by a random number generated by a uniform distribution with specified lower and upper limits. One simple way to set the lower and upper limits is using fixed values, like -0.1 and 0.1. In a more adaptive way, the limits are set according to the column size of weight matrix (Glorot and Bengio, 2010). Take weight matrix as an example, the lower and upper limits can be set as and . This strategy only works for matrixes, and vectors, like feature vectors and bias vectors, are still initialized using fixed lower and upper limits. In this way, the lower and upper limits do not need to be tuned when the size of martrix or vectors is changed.
2. TRAINING UNIT
As is well known, the goal of neural network language models is to learn the distribution function of word sequences in a language, and the words from a data set are usually treated as a single and long sequence. When traing neural network language models on training data set , denoted as , the parameters of neural network language model are updated each update block, say words each update block. For recurrent network language models or lstm ones, the error should be back-propagated. The computation is much expensive to back-propagated the error through all the whole sequence, therefore, the truncated bptt method is used, this is to back-propagate error through only a few previous steps at each updating, for instance steps. The procedure to back-propagate errors is illustrated in Figure 1, and is the number of words already processed before this update block.
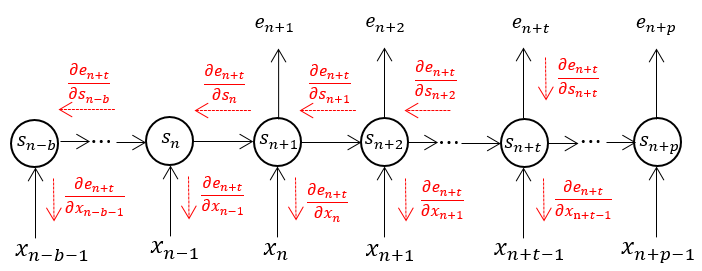
Figure 1. Back-propagate error in an update block
However, when the data set is dealt with as a set of individual sentences, it is feasible to back-propagate errors through a whole sentence without truncation although sometimes several sentence may be very long and almost the same perplexity is achieved. In addition, it makes more sense to take a sentence as a individual when processing languages. For a sentence , a start mark and end mark usually are added before ruuning language model on it. The errors will only been back-prograted inside this sentence and not truncation needed, as showed in Figure 2.
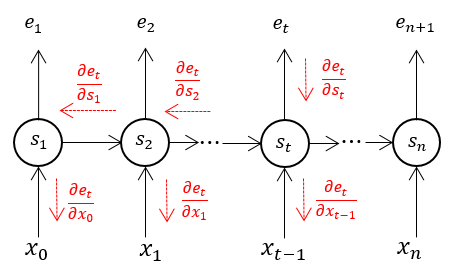
Figure 2. Back-propagate error within a sentence
The words inside a sentence have more tight relation with one another than with words in other sentence, but the relation with words outside sentence should not be ignored, espicially the ones in the same paragraph. Fortuntely, The cache technique can be adopted to deal with this problem.
3. INPUT LEVEL
According to the composition of words, there are mainly two kinds of language. In one kind of languages, words are formed by one or more characters, like English or French; In the other kind of languages, one word is one character, such as Chinese or Korean. For the second kind language, there is no need to talk about the input level for language models becaues characters and words are the same in these languages. The input level of the first kind language can be either word or character. When taking character as input level, the vocabulary size is usually less than 50 which is much smaller than the one when using word as input level (around servel ten thousands), and the training and test will be faster. However, the sequence will be much longer when spliting words into characters, and the calculated amount will be increased. Moreover, many speed-up techniques, like importance sampling (Bengio and Senecal, 2003) and hierarchical archietecture method (Morin and Bengio, 2005), have been proposaled which mainly aim at decreasing the calculated amount caused by vocabulary size. In fact, with speed-up techniques, neural network language models, whose input level is word, run much fater during both training and test than the ones whose input level is character. Therefore, it is better to take word as input level in consideration of calculated amount.
4. UNKNOWN WORDS
Unknown words, which is also called words out of vocabulary, is an unavoidable problem when building a language model, because it is impossible to include all words of a language while building vocabulary. When neural network models are applied into language modeling, the computation is very expensive, As a matter of fact, it takes around one day to train nerual network language models even on a small corpus like Brown Corpus. One of the factors, which lead to the great computational burden of neural network language models, is the size of vocabulary. In order to reduce the calculated amount, not all the words from training set are added into pre-build vocabulary. The words out of vocabulary are all treated as unknown words and share one feature vector, but this will decrease the performance of neural network language, in another way, increase perplexity.
After some speep-up techniques are proposed, the size of vocabulary is not a problem any more and all words from training set are added into vocabulary, and there is no unknown words during training. However, some words in validation set or test set may be not included in the vocabulary and this is what always happens. The common way to deal with this problem is to assign a feature vector, whose elements are all zero, to those words out of vocabulary, and do not take those words into account when count the total number of words and the probability of word sequence. Take a word sequence as an example, assuming there is only one word which is out of vocabulary. Before running nerual network language model on this word sequence, a start and end mark should be added and make them as and respectively. The inputs and outputs of neural network language model are as showed in Figure 3, and is the previous context of word , i.e., . When calculating the entropy or perplexity, the total number of words is , because word and start mark are not counted. And the probability of this word sequence is:
the conditional probability of word is excluded.
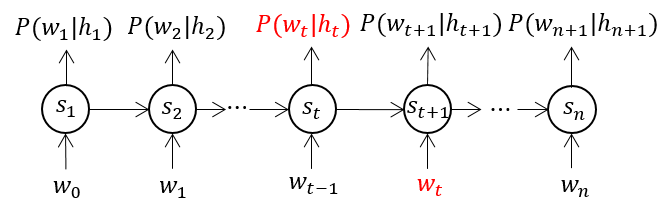
Figure 3. How to deal with unknown words
5. OTHERS
There are some programing tricks for building neural network language models with codes. First, using one dimension arrays for weight matrix will be much faster than using two dimension arrays; Second, allocate variables with enough memeory before training or test, and avoid allocate or reallocate memory during training or test.



